
前回は、Cinebench R23などのベンチマーク結果を紹介しましたが、今回は著者が本業での使用している計算科学ソフトLAMMPSでのベンチマークを実施したので、結果を紹介したいと思います。
ベンチマーク内容について
今回は、計算科学で利用される分子動力学計算ソフトLAMMPSのベンチマークを実施しました。
分子動力学法とは、物理や化学分野で使用されるコンピュータシミュレーション手法の1つです。分子動力学計算は、原子や分子を粒子に見立て粒子間の相互作用を古典力学に基づいて計算することで、時間経過に伴う粒子の振る舞いや物性を計算する手法です。
今回のベンチマークでは、LAMMPSのベンチマークとして付属している5種類の計算を、CPUの並列数を1 ~ 16 並列で実施しました。
実行環境
今回のベンチマークを行うにあたり、Windows 11環境ではMPIの設定が煩雑だったためubuntu環境を構築し実施しています。環境とLAMMPSのビルド条件は以下の通りです。
| Model | MINISFORUM NAB6 |
| CPU | Intel Core i7 12650H |
| Memory | DDR4-3200 16 GB (Dual Channel) |
| OS | Ubuntu 22.04.2 LTS |
| Compiler | Intel oneAPI DPC++/C++ Compiler |
| MPI | Intel MPI |
| FFT Library | Intel Math Kernel Library |
ベンチマーク結果
原子数 32,000 のモデルでは、いずれの計算内容でも 6 スレッドまで、ほぼ直線的に計算のパフォーマンスが上昇しました。
Core i7 12650HのP-coreが6 コアであることから推測すると、各P-coreに対しシングルスレッドでジョブを投入することで、比較的高効率に計算しているのではないかと考えます。
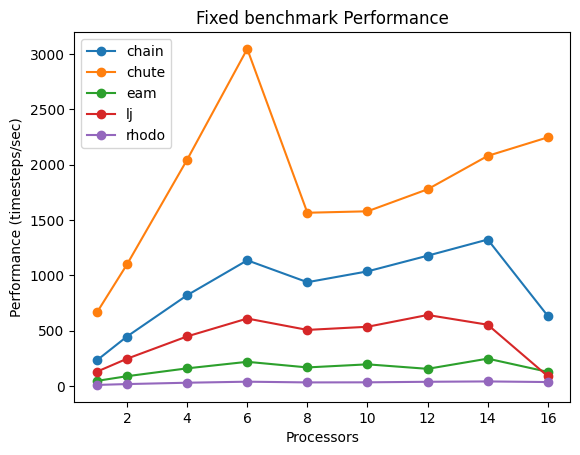
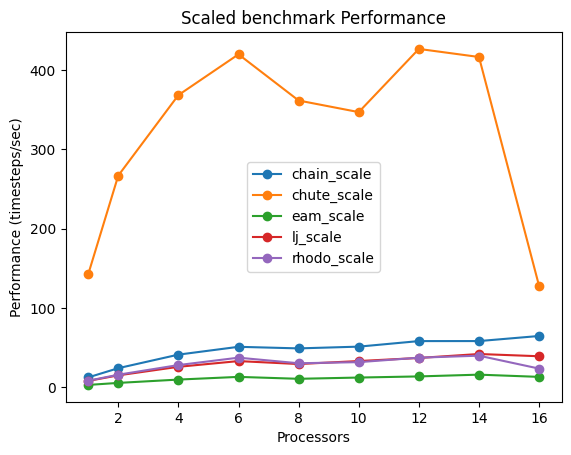
一方、原子数 128,000のモデルでも32,000 原子モデルと同様に、6スレッドまではパフォーマンス改善が見られ、それ以上の並列数でのパフォーマンスの改善は鈍くなる傾向が顕著にみられました。
また、小規模モデルに比べ、原子数が増えた場合のパフォーマンスの改善は直線的ではなく、スレッド数の増加に伴う改善幅が小さくなる傾向でした。
まとめ
今回、MINISFORUM NAB6 (CPU : Core i7 12650H)を使用して、Linux環境下でのLAMMPS実行時のパフォーマンスをベンチマークしました。
その結果、32,000 程度の原子数であれば6スレッドでの並列計算が比較的高効率であり、それ以上の並列計算に伴うパフォーマンス改善は緩やかであることがわかりました。
CPU自体はハイパースレッディングに対応していますが、今回のような用途ではハイパースレッディングに伴う実質のパフォーマンス改善は限定的であると推測します。
また、6スレッドから8スレッドへ並列数が増えた場合、ほぼ全ての条件でパフォーマンスの低下が発生しました。これは、8スレッドでの計算が P-Core 6 スレッド + E-Core 2 スレッドで実行されたためではないかと予測します。
以上が今回の一旦の結論です。
今後は、メモリ帯域幅やE-Coreをオフにした場合のパフォーマンスもチェックできれば検証してみたいと思います。

コメント